A French translation of this page is also available thanks to Vicky Rotarova.
What’s in a name? Everything. When a good name gets manipulated for bad intentions, it costs money, trust, time and resources. UCAPI detects confusable and visual similarity in strings – tactics used by fraudsters to manipulate everything from Internationalized Domain Name (IDN) and page content to user-interfaces and dialog boxes - and helps protect your good name from bad people.
Contact us now for more information.
As Internet software and service offerings continue to globalize, a better understanding of the threats around visual spoofing is required to help product teams make safe and secure designs. As Web browsers, mobile devices, and applications evolve to support Unicode in all facets, Casaba saw the need to investigate problem areas of string confusability more closely. During our research, we registered several popular domain-name lookalikes with IDN, and reported many vulnerabilities to software vendors including Apple, Google, Microsoft, and Mozilla. Defenses not implemented in major applications (or at the registrar level) create openings for well-planned phishing attacks. In looking beyond IDNs, the attack surface for visual spoofing is even broader.
Clearly, the threat of a widespread visual spoofing attack is still all too real and accessible. To this end, Casaba developed UCAPI - a solution to analyze strings for confusable characters, and compare two strings for visual appearance. Many costly examples in which confusable and visual string similarity can be used include:
To a human reader, some of the following letters are indistinguishable from one another while others closely resemble one another:
To a computer system however, each of these letters has very different meaning. The underlying bits that represent each letter are different from one to the next. How then, could a software vendor possible implement a solution that guaranteed expected visual appearances?
Implemented as a cross-platform core library solution developed in C and C++ (with language-specific wrappers), UCAPI hinders attacks like these by recognizing visually confusable characters and similar strings from the wide variation of languages being employed. Partially based on the specification defined by Unicode TR39, UCAPI can provide software vendors with safety options not currently available in Win32 or .NET libraries. UCAPI is not Windows-specific however, as it supports BSD and Linux flavors as well. |
Clear Vectors within Reach of Attack
As technology continues to become more and more a part of our consumer and business worlds, people are making important decisions based on what they visually see on their screens. Whether it's an email message on a PC, a Web browser on a Mac, or a social networking URL on a mobile device, we believe that people respond based on what they see. With most major computing platforms and mobile devices supporting Unicode attackers have capability to use lookalike characters to fool people in many different contexts.
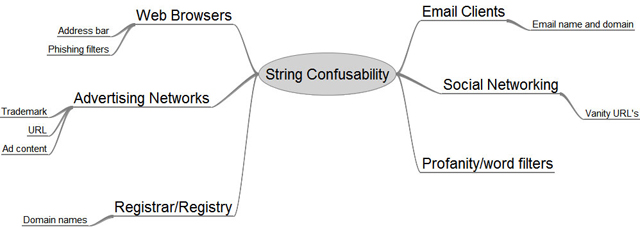
The image here depicts just some of the scenarios where 'string confusability' can play an important role in the end-user decision-making process. A well-designed phishing, pharming or spam campaign can exploit the use of lookalike characters in all of these scenarios to fool end-users. To combat these fraudulent attacks on brands and names, Casaba has developed the UCAPI library which can help you minimize the threat of visual attacks in your Internet applications.
Consumer User-Agents (Web browsers and email clients)
Web browsers and email clients are the portals to our ubiquitous information. It’s no wonder their the constant target of attack. Phishing attacks continue to evolve with email spam campaigns that look more and more like they're coming from authentic sources. As IDN's continue to become more mainstream and new glTLDs emerge phishers will have renewed ammunition at their disposal to craft fraudulent messages and domain names that look visually identical to their legitimate counterparts. Web browsers, email clients, and anti-phishing platforms could implement confusability detection now to start collecting data on IDN abuse and gaining insight into these attack vectors - before a widespread attack occurs.
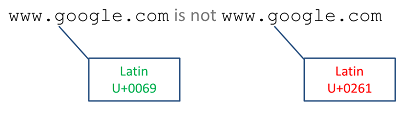
Email addresses have long been confined to ASCII, but there will most certainly be a time when they're opened up to UTF-8 and international characters. In preparing for that transition, email client designers need to anticipate and handle the case of visually identical email addresses. If not, end users could easily be fooled. Digital certificates provide good mechanisms for proving authenticity of a message; however, such certificates also support Unicode and are therefore vulnerable to the same attacks.

Domain Name Registry and Registrar
The Internet registries and registrars are in a unique position to handle the problem of visual spoofing attacks in IDN. We can think of a number of ways that this technology could be applied to address the problem of attackers maliciously registering lookalike domain names. A registry could work in partnership with registrars to detect potentially confusable domain names during registration. Perhaps more effective, this partnership could be used to detect when a new domain registration is visually similar or identical to one that already exists. With millions of domains registered this may not seem the best use of resources. Instead, a visual spoofing protection service could be offered for domain names who sign up for it, or as a protection against the world's top 10,000 domains. As a registry or registrar, you could assess your capability around this threat-area by asking a few questions:
- Do I have visibility into fraudulent domain name registrations leveraging IDN?
- Do I have a method to detect and prevent an IDN spoof of a popular domain name?
- Do I understand how the threats to IDN might evolve over time?
Social Networking Platforms (vanity URL)
In today’s Internet-connected world, domain names and URLs are real estate, and social networking sites like Facebook, Twitter, and LinkedIn offer some form of a vanity URL to consumers. A social networking service might want to allow the registration of vanity URI's using international characters, but can't risk the security threat posed by the endless ways in which they can be manipulated to visual fraud and confusion. Because Unicode characters are well supported in the path portion of a browser's URI display, a well-crafted vanity URI could easily fool victims and be the landing page for a phishing attack. Modern desktop and mobile browsers will display characters after the first '/' in their pure Unicode form, making for good usability but also increasing the opportunities for phishing and spoofing.
| For example, | can be spoofed using completely different Unicode: | |
 |
||
Many online systems and video games featuring instant messaging and user forums employ filter security in order to prevent the use of violent and profane words. There are however, many simple ways to bypass such filters - such as the use of spacing and punctuation between letters in a word (e.g. c_r_a_p), misspellings that give the same effect (e.g. crrap), and using confusable characters which have no visual side-affect (e.g. crap).
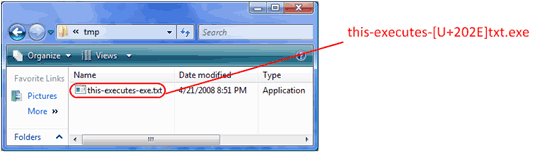
Many Internet applications give security decisions to their users in the form of dialog boxes. For example, when a user downloads a file through a Web browser, they're asked to confirm their decision. When they launch the file, they may also be presented with a dialog box asking for confirmation (if the file is an untrusted application. However, a clever attack may use special BIDI or other characters that reverse the direction of text to fool end users into executing a harmful file that looks innocent.
Consider an advertising network that needs to mitigate malicious ads, malvertisements, by protecting brand name trademarks from being registered by anyone other than their owner. An attacker could place an ad that bypasses trademark filters by using confusable characters that fool users into visiting a phishing site. For example, "Download Microsoft Service Pack 1 for Windows 7 here" where the trademarked name 'Microsoft' was crafting using non-English script.
![]() UCAPI is a solution that transcends all these issues with its detection of confusable characters and visually similar strings. Using a high-performance native library with ultra-fast sub-nanosecond lookups, its scalable, cross-platform capabilities create a roadmap that provides coverage for all these scenarios - and even more attack vectors not mentioned here.
UCAPI is a solution that transcends all these issues with its detection of confusable characters and visually similar strings. Using a high-performance native library with ultra-fast sub-nanosecond lookups, its scalable, cross-platform capabilities create a roadmap that provides coverage for all these scenarios - and even more attack vectors not mentioned here.